自定义存储
默认情况下,LlamaIndex隐藏了复杂性,让您在不到5行代码中查询数据:
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = GPTVectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("Summarize the documents.")
在幕后,LlamaIndex还支持可替换的存储层,允许您自定义摄取的文档(即Node对象),嵌入向量和索引元数据的存储位置。
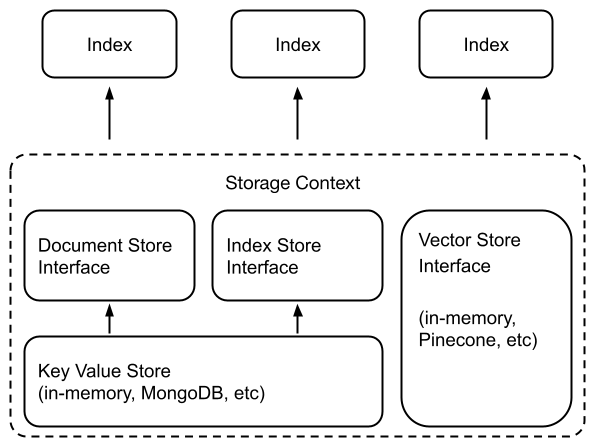
低级API
为此,我们使用更低级的API,而不是高级API,
index = GPTVectorStoreIndex.from_documents(documents)
这样可以提供更细粒度的控制:
from llama_index.storage.docstore import SimpleDocumentStore
from llama_index.storage.index_store import SimpleIndexStore
from llama_index.vector_stores import SimpleVectorStore
from llama_index.node_parser import SimpleNodeParser
# create parser and parse document into nodes
parser = SimpleNodeParser()
nodes = parser.get_nodes_from_documents(documents)
# create storage context using default stores
storage_context = StorageContext.from_defaults(
docstore=SimpleDocumentStore(),
vector_store=SimpleVectorStore(),
index_store=SimpleIndexStore(),
)
# create (or load) docstore and add nodes
storage_context.docstore.add_documents(nodes)
# build index
index = GPTVectorStoreIndex(nodes, storage_context=storage_context)
# save index
index.storage_context.persist(persist_dir="<persist_dir>")
# can also set index_id to save multiple indexes to the same folder
index.set_index_id = "<index_id>"
index.storage_context.persist(persist_dir="<persist_dir>")
# to load index later, make sure you setup the storage context
# this will loaded the persisted stores from persist_dir
storage_context = StorageContext.from_defaults(
persist_dir="<persist_dir>"
)
# then load the index object
from llama_index import load_index_from_storage
loaded_index = load_index_from_storage(storage_context)
# if loading an index from a persist_dir containing multiple indexes
loaded_index = load_index_from_storage(storage_context, index_id="<index_id>")
# if loading multiple indexes from a persist dir
loaded_indicies = load_index_from_storage(storage_context, index_ids=["<index_id>", ...])
您可以通过一行更改来自定义底层存储,以实例化不同的文档存储,索引存储和向量存储。请参阅大多数我们的向量存储集成都将整个索引(向量+文本)存储在向量存储本身中。这具有不必显式持久化索引的主要好处,因为向量存储已经托管并将数据持久化到我们的索引中。支持此做法的向量存储包括:ChatGPTRetrievalPluginClient、ChromaVectorStore、LanceDBVectorStore、MetalVectorStore、MilvusVectorStore、MyScaleVectorStore、OpensearchVectorStore、PineconeVectorStore、QdrantVectorStore、RedisVectorStore和WeaviateVectorStore。以Pinecone为例的一个小示例如下:导入pinecone,从llama_index中导入GPTVectorStoreIndex和SimpleDirectoryReader,从llama_index.vector_stores中导入PineconeVectorStore,创建Pinecone索引,定义特定于此向量索引的过滤器,构造向量存储,创建存储上下文,加载文档,创建索引,重建/加载索引。