🔬 Evaluation
LlamaIndex提供了几个关键模块来评估文档检索和响应合成的质量。以下是每个组件的一些关键问题:
文档检索:源与查询相关吗?
响应合成:响应是否与检索的上下文匹配?它也与查询匹配吗?
本指南介绍了LlamaIndex中的评估组件如何工作。请注意,我们目前的评估模块不需要基础真实标签。评估可以通过查询、上下文、响应和LLM调用的某种组合来完成。
响应+上下文的评估
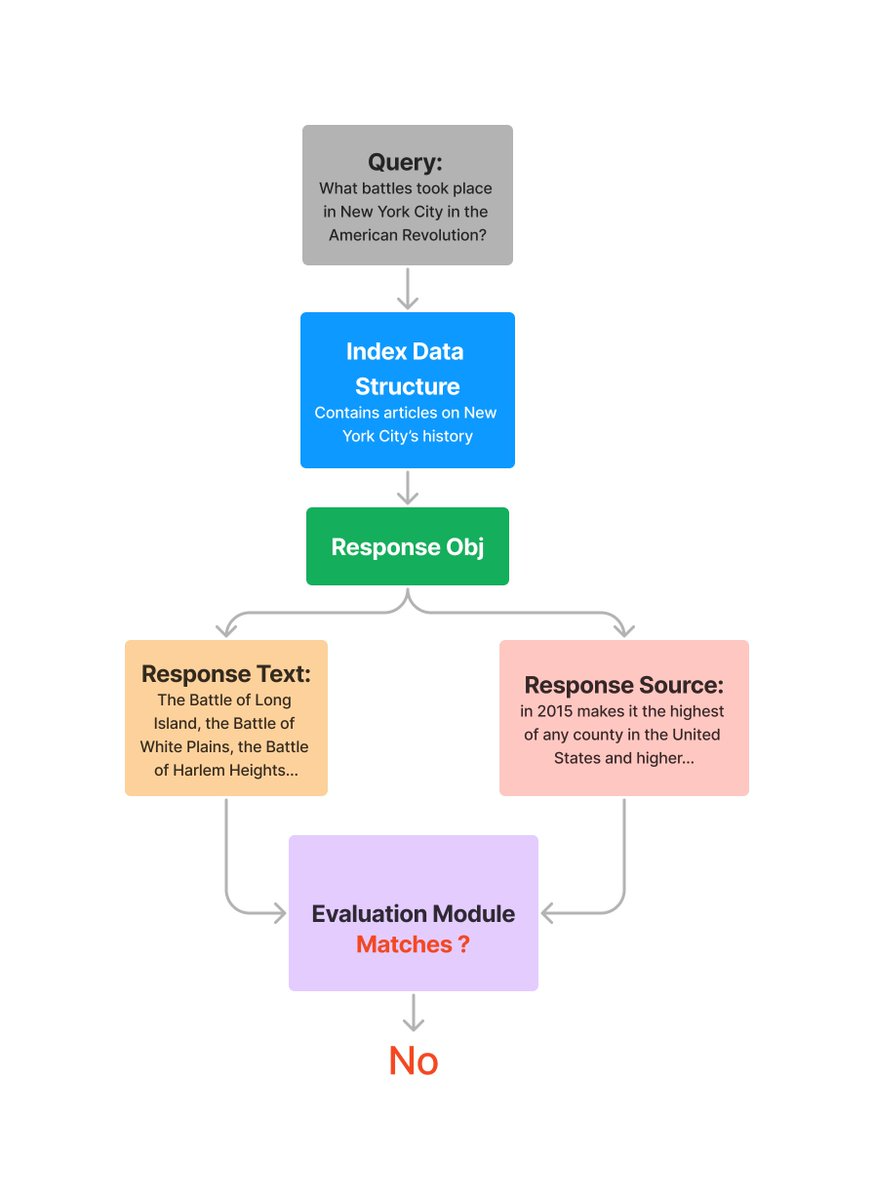
每个query_engine.query调用返回的响应都包括合成的响应和源文档。
我们可以评估响应与检索源的响应,而不考虑查询!
这样可以测量幻觉 - 如果响应与检索的源不匹配,这意味着模型可能会“幻想”一个答案,因为它没有根据提示中提供的上下文来回答。
这里有两种子模式的评估。我们可以获得一个二进制响应“YES”/“NO”,表示响应是否与任何源上下文匹配,也可以获得跨源的响应列表,以查看哪些源匹配。
二进制评估
此模式的评估将返回“YES”/“NO”,如果合成的响应与任何源上下文匹配。
from llama_index import GPTVectorStoreIndex
from llama_index.evaluation import ResponseEvaluator
# build service context
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-4"))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
# build index
...
# define evaluator
evaluator = ResponseEvaluator(service_context=service_context)
# query index
query_engine = vector_index.as_query_engine()
response = query_engine.query("What battles took place in New York City in the American Revolution?")
eval_result = evaluator.evaluate(response)
print(str(eval_result))
您将获得“YES”或“NO”的响应。
图表
来源评估
此模式的评估将为每个源节点返回“YES”/“NO”。定义评估器 evaluator = ResponseEvaluator(service_context = service_context)
#查询索引 query_engine = vector_index.as_query_engine() response = query_engine.query(“美国革命时期纽约市发生了哪些战斗?”) eval_result = evaluator.evaluate_source_nodes(response) 打印(str(eval_result))
您将获得一个“是”/“否”的列表,对应于response.source_nodes中的每个源节点。