Response Synthesis
LlamaIndex offers different methods of synthesizing a response from relevant context. The way to toggle this can be found in our Usage Pattern Guide. Below, we visually highlight how each response mode works.
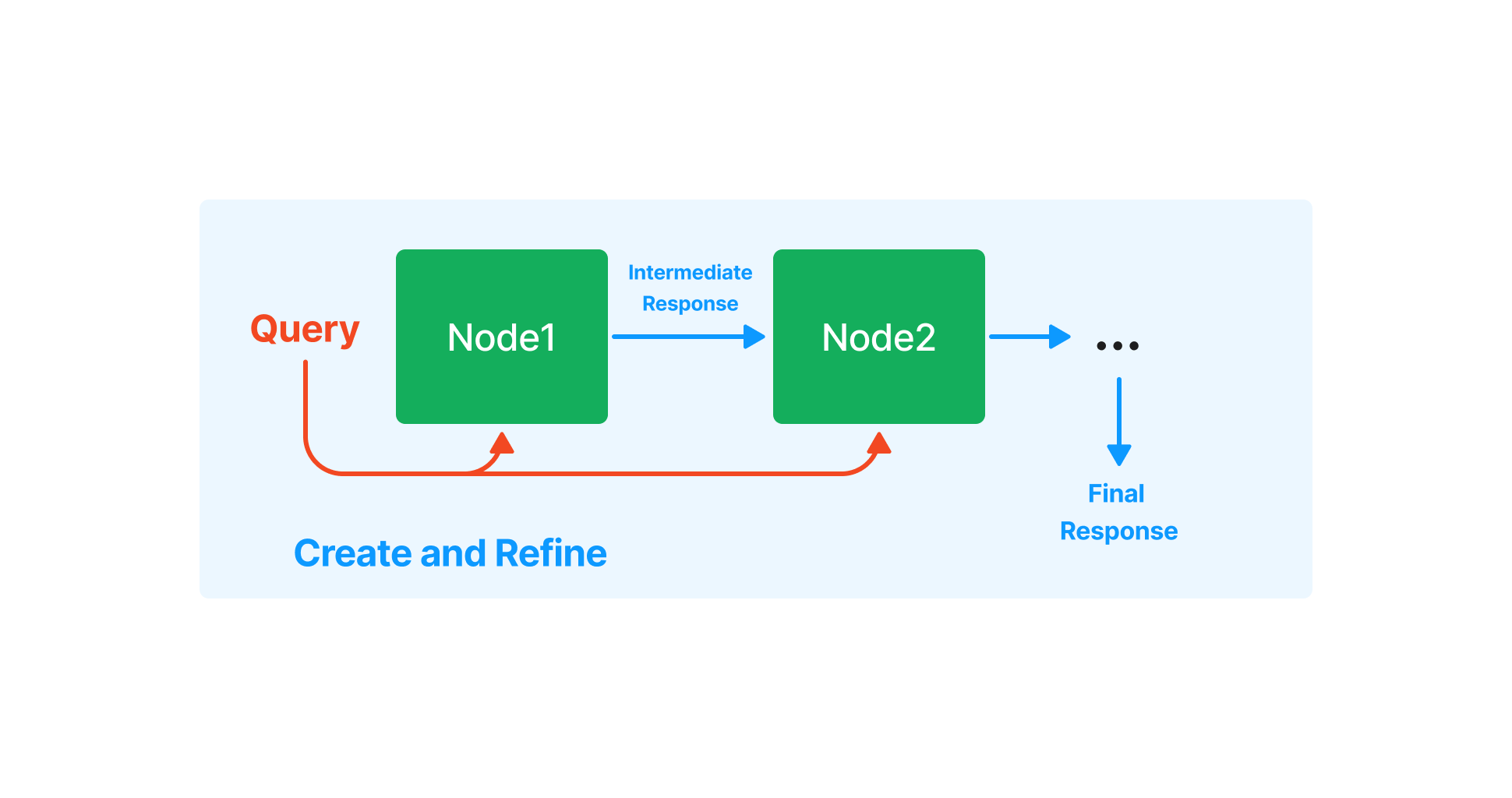
Refine
Refine is an iterative way of generating a response. We first use the context in the first node, along with the query, to generate an initial answer. We then pass this answer, the query, and the context of the second node as input into a "refine prompt" to generate a refined answer. We refine through N-1 nodes, where N is the total number of nodes.
[Default] Compact and Refine
Compact and refine mode first combine text chunks into larger consolidated chunks that more fully utilize the available context window, then refine answers across them.
This mode is faster than refine since we make fewer calls to the LLM.
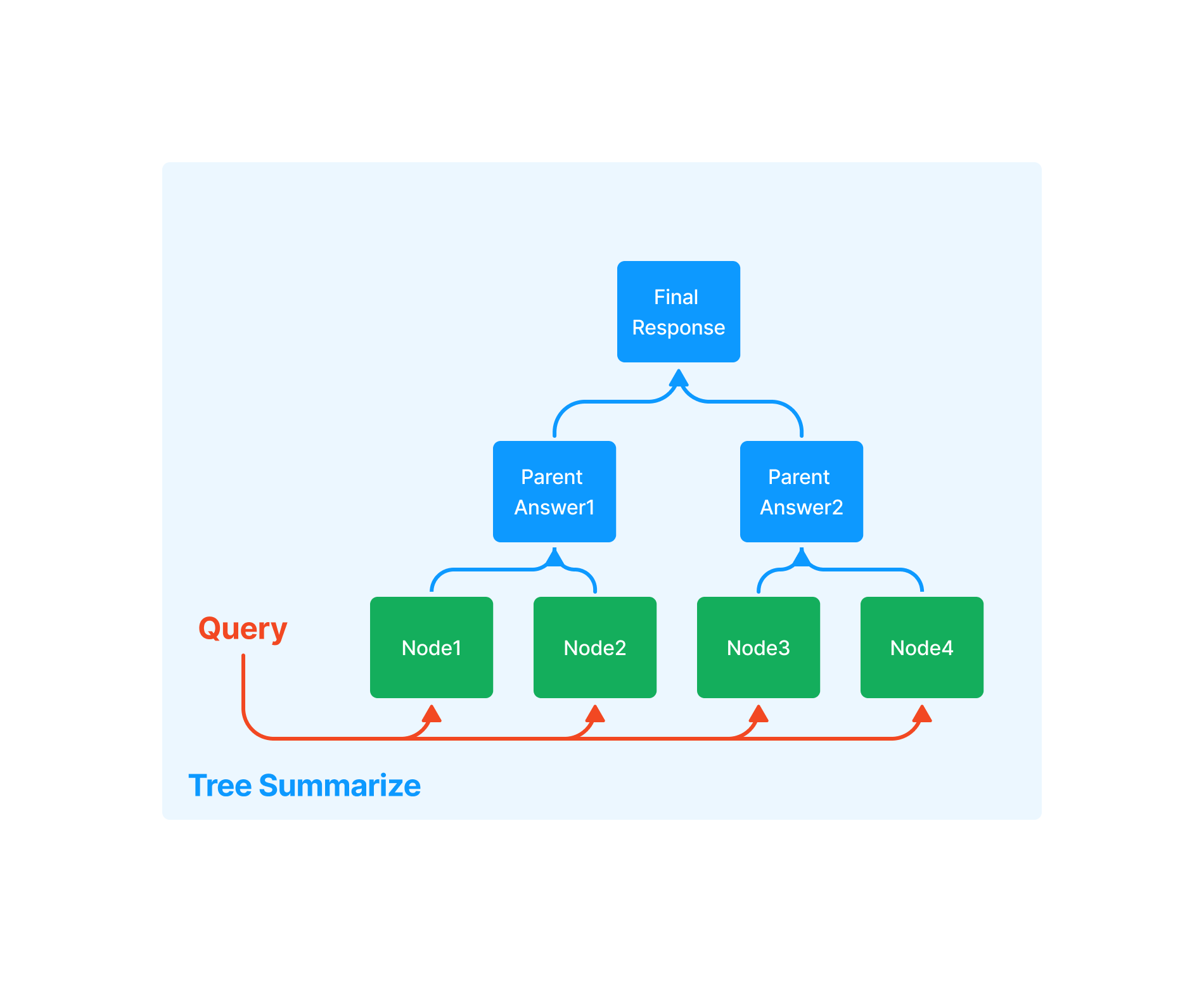
Tree Summarize
Tree summarize is another way of generating a response. We essentially build a tree index over the set of candidate nodes, with a summary prompt seeded with the query. The tree is built in a bottoms-up fashion, and in the end the root node is returned as the response.
Simple Summarize
Simply combine all text chunks into one, and make a single call to the LLM.
Generation
Ignore all text chunks, make a single call to the LLM with just the query and no additional context.